


- Understanding IBM MQ Native HA
- Native HA vs. IBM MQ Clustering: Clearing Up the Confusion
- How IBM MQ Clustering and Uniform Clusters Differs
- Native HA vs. Multi-Instance Queue Managers: Key Differences
- 4 Administration Tips for Managing High Availability Environments
- The Critical Role of Monitoring in IBM MQ Native HA Environments
- Best Practices for Implementing IBM MQ Native HA
- Additional Considerations and Future Outlook
IBM MQ Native HA: Enhancing Messaging Resilience in Modern Architectures
In today’s digitally connected world, enterprise messaging systems must be both highly available and resilient. IBM MQ—a leader in message-oriented middleware—provides robust messaging capabilities that ensure reliable data exchange between applications. One of the key features that help guarantee uninterrupted messaging is Native High Availability (HA). This article explores IBM MQ Native HA in depth, clarifies common misconceptions by comparing it with IBM MQ clustering and Multi Instance Queue Managers, highlights the critical role of monitoring, and offers best practices for optimal deployment.
Understanding IBM MQ Native HA
What Is IBM MQ Native HA?
IBM MQ Native HA refers to the built-in capability within IBM MQ designed to provide seamless failover where data such as messages are replicated. There are multiple running instances with a leader or active instance plus others which are ready to take over in the event of a failure.
In a Native HA setup, three Kubernetes pods each host an instance of the queue manager. The active queue manager handles message processing and logs updates to its recovery log. Simultaneously, it transmits these updates to the two replica instances, which independently write the data to their own recovery logs. After acknowledging the updates, each replica synchronizes its queue data based on the replicated log. In the event of a failure affecting the active queue manager’s pod, one of the replicas seamlessly assumes the active role, ensuring continuity with up-to-date data.
Key features of IBM MQ Native HA include:
- ActiveReplicas Configuration: Only one instance (the active queue manager) handles messages at any given time. The Replica instances receive data from the active instance and updates its own data and monitors for failures and takes over when needed.
- Data Replication: The active queue manager instance replicates its data, including messages and configuration information, to the replica instances. Each instance maintains its own independent storage. This replication ensures data durability and enables a replica to take over quickly in case of a failure.
- Automatic Failover: Built-in detection mechanisms trigger an automatic takeover by the standby instance when the active instance becomes unavailable.
- Reduced Downtime: Because the failover is automated, disruptions to messaging services are minimized.
A simplified diagram of this architecture is shown below:
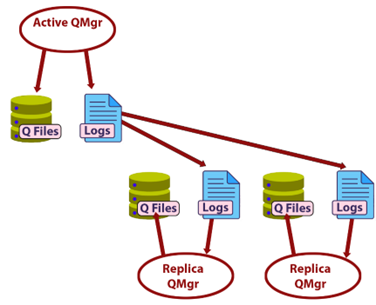
Figure 1: High-Level Architecture of IBM MQ Native HA (3 pods). For more detailed technical information, refer to the IBM MQ documentation.
Native HA vs. IBM MQ Clustering: Clearing Up the Confusion
Many organizations mistakenly conflate IBM MQ Native HA with IBM MQ clustering. Although both approaches aim to improve system reliability, they serve different purposes and operate in distinct ways.
What Is MQ Clustering?
IBM MQ clustering typically refers to a broader IT strategy where multiple nodes (servers or instances) work together to ensure application continuity. In the context of IBM MQ, clustering often implies a group of queue managers that work together to balance the load and offer fault tolerance. However, unlike Native HA, IBM MQ clustering is not a HA solution. MQ Clustering is generally more focused on workload distribution rather than instantaneous high availability. IBM MQ Clustering is primarily for ease of administration and load balancing.
How HA and Clustering Configuration Differs
In IBM MQ, a node refers to a system running an operating system and HA software. The terms computer, system, machine, partition, or blade may also be used interchangeably in this context. IBM MQ supports both standby and takeover configurations, including mutual takeover, where all nodes in the cluster actively run an IBM MQ workload.
A standby configuration is the most basic HA cluster setup, where a single active node processes workloads while a standby node remains idle, only taking over if a failure occurs. This is often called cold standby and requires dedicated hardware redundancy. To optimize resources, an N+1 configuration extends this model by allowing multiple worker nodes to share a single standby node, which can assume the workload of any failed node.
A takeover configuration is more advanced, as all nodes actively handle workloads, and critical workloads can shift between nodes in case of failure. A one-sided takeover configuration introduces some efficiency by allowing the standby node to perform nonessential, nontransferable work, while still being available for failover. In contrast, a mutual takeover configuration (also called Active/Active) ensures that all nodes handle essential workloads, allowing them to take over seamlessly if another node fails.
Regardless of the configuration, it is essential to consider peak load capacity when designing IBM MQ clustering. Nodes responsible for failover must have sufficient resources to absorb additional workloads without degrading performance. Proper capacity planning ensures that failover does not introduce bottlenecks or service disruptions.
How IBM MQ Clustering and Uniform Clusters Differs
In an IBM MQ uniform cluster, primary and secondary repositories are not required in the same way as traditional MQ clusters. Uniform clusters are designed for high availability and workload balancing across queue managers, and they rely on identical configurations rather than full and partial repositories.
However, in traditional MQ clusters, full repositories are essential for maintaining cluster information, and it’s common to have two queue managers hosting full repositories for redundancy. These repositories synchronize with each other to ensure availability.
Uniform clusters simplify administration by using automatic configuration and clustering. This removes the dependency on specific queue managers and focuses on horizontal scaling.
For more information, please reference IBM Documentation.
A Comparative Table
Below is a table comparing IBM MQ Native HA with typical HA clustering configurations:
| Feature | IBM MQ Native HA | IBM MQ Clustering |
|---|---|---|
| Purpose | Provides rapid failover and minimal downtime. | Ease of Administration and Load Balancing. |
| Architecture | Active/Passive configuration. Replicates queue and log data across multiple instances. |
Distributes the workload of messages being placed on a queue. |
| Failover Mechanism | Automated and near-instantaneous failover. | An application can place a message on any qmgr that is part of the cluster and it will be routed to the qmgr that queue is local to. |
| Complexity | Relatively straightforward to set up. | Requires additional qmgrs called Primary Repositories to manage the cluster. |
| Performance Impact | Low, as only one instance is active at any time. | Balances load across nodes with very little overhead. |
| Use Case | Mission-critical messaging with stringent uptime needs. | Scenarios needing both load balancing and resilience. Can be used inside and outside containers. |
Understanding these differences is essential when designing your messaging infrastructure. While both models enhance resilience, IBM MQ Native HA is particularly suited for environments where minimal downtime and quick failover are paramount.
Native HA vs. Multi-Instance Queue Managers: Key Differences
While IBM MQ Native HA and multi-instance queue managers both aim to provide high availability, they are fundamentally different in architecture and operation. IBM MQ Native HA is specifically designed for containerized environments and leverages replicated data across multiple pods to provide seamless failover without relying on shared storage. It operates with an active-active replication model, where logs and queue files are consistently replicated across instances, ensuring resilience even in cloud-native deployments.
On the other hand, multi-instance queue managers use a shared file system (such as NFS or GPFS) that requires at minimum an NFS v4 connection to enable failover between an active and a standby instance. In this model, only one queue manager is active at a time, and the standby instance takes over by mounting the same storage location if the active instance fails. While multi-instance queue managers are more suited for traditional, on-premises environments with shared storage, Native HA is optimized for cloud-native, Kubernetes, or OpenShift deployments, eliminating the dependency on external storage systems and offering faster failover with built-in data replication.

4 Administration Tips for Managing High Availability Environments
Ensuring high availability in IBM MQ requires some special administration techniques. Here are three essential administration tips to help maintain seamless IBM MQ operations, no matter which of the HA scenarios you choose:
- Administration and Monitoring Consolidation
Relying on separate tools for monitoring and administration can lead to inefficiencies, especially during failovers. A best practice is to utilize a solution like Infrared360® that combines True Real-Time™ monitoring, administration, and policy enforcement into a single interface, eliminating the need for multiple disconnected tools. - Automate Failover and Recovery Processes
A well-managed high availability environment requires more than just detecting a failure—it needs automated response mechanisms. Infrared360 provides automated instance switching, ensuring that monitoring and administration automatically follow the failover event. This prevents the need for manual intervention, reducing downtime and improving resilience. - Ensure Proactive Issue Detection and Resolution
High availability isn’t just about reacting to failures—it’s about preventing them. Infrared360 offers advanced diagnostics, historical data tracking, and capacity planning tools that help identify potential issues before they lead to failovers. By continuously analyzing queue performance, throughput trends, and message delays, administrators can take proactive steps to optimize their IBM MQ environment. - Role Based Access Control (RBAC)
RBAC is crucial for maintaining the integrity and security of IBM MQ monitoring and administration, especially within a High Availability (HA) deployment. In an HA environment, where multiple queue managers work in concert to ensure continuous service, granular control over who can access and modify configurations is paramount. In Infrared360, Trusted Spaces™ is our RBAC feature that allows administrators to define specific roles with limited privileges, preventing unauthorized changes that could disrupt the delicate balance of the HA setup. This minimizes the risk of accidental or malicious alterations that could lead to service outages, data corruption, or security breaches.
Furthermore, in complex MQ deployments, particularly those involving HA, different teams or individuals may be responsible for specific aspects of monitoring and administration. For instance, a network operations team might need read-only access to monitor queue depths and performance, while a dedicated MQ administration team requires broader privileges to manage configurations and resolve issues. Trusted Spaces™ enables this segregation of duties, ensuring that each user has the necessary permissions to perform their tasks without compromising the overall security and stability of the IBM MQ HA environment. This controlled access is vital for maintaining compliance, auditing changes, and ultimately, ensuring the resilience of the messaging infrastructure.
The Critical Role of Monitoring in IBM MQ Native HA Environments
Even with robust native high availability, it is vital to implement comprehensive monitoring to ensure that all components of your messaging environment are functioning optimally. Monitoring plays several critical roles:
Detecting and Responding to Failovers
Automated failover is a central feature of IBM MQ Native HA, but without active monitoring, system administrators may not be aware of repeated failover events or subtle performance degradations that can indicate deeper issues. Effective monitoring solutions should:
- Automatically Detect Failover Events: The tool should recognize when the active queue manager goes down and the standby instance takes over.
- Switch Monitoring Focus: It must dynamically adjust to monitor the new active instance without manual intervention.
- Alert Administrators: Rapid notifications via email, SMS, or integrated dashboards are essential to prompt timely investigations.
Outside of Failovers
Aside from failover monitoring aspects, it’s critical to employ proper monitoring and management of your Native HA environment to ensure the health of your system, identify potential issues, and recover quickly from failures. Monitoring the queue managers in your active pods helps you detect problems early, such as message throughput issues, error rates, or queue performance issues which can lead to situations that result in a failover.
Enhancing Administrative Capabilities
A robust monitoring solution should not only alert you to issues but also provide administrative tools to manage the environment remotely. Features such as historical performance trends, capacity planning, and detailed diagnostics enable proactive management of the messaging infrastructure.
Infrared360 and Complementary Monitoring Solutions
Infrared360 is an example of a monitoring solution that offers capabilities particularly beneficial for IBM MQ Native HA environments. Its features include:
- Automated Instance Switching: Infrared360’s monitoring engine is designed to seamlessly follow failover events, ensuring continuous oversight.
- Administrative Dashboards: It offers intuitive dashboards that allow administrators to drill down into performance metrics, queue depth, message throughput, and more.
- Integration with Other Tools: Infrared360 can be integrated with enterprise IT management systems, ensuring that all aspects of your messaging infrastructure are visible in a single pane of glass.
For organizations seeking additional insights or complementary monitoring capabilities, Avada Software provides purpose-built solutions for IBM MQ environments. Visit our overview on monitoring IBM MQ Native HA and cloud-native environments to see how Infrared360 supports Kubernetes-based deployments like IBM MQ Native HA.
Monitoring Best Practices
- Regular Testing: Schedule routine failover tests to ensure that monitoring tools correctly detect and follow the failover process.
- Threshold Setting: Define sensible thresholds for alerting on key metrics such as queue depth, message latency, and resource utilization.
- Historical Data Analysis: Use monitoring data to identify trends and proactively adjust capacity or configurations.
Best Practices for Implementing IBM MQ Native HA
A successful IBM MQ Native HA implementation hinges on careful planning, rigorous testing, and continuous monitoring. Below are some best practices to consider:
1. Infrastructure Planning and Design
- Shared Storage Reliability: Ensure that the shared file system used by the active and passive queue managers is both robust and redundant. Consider using enterprise-grade storage solutions with built-in redundancy features.
- Network Redundancy: Configure your network to avoid single points of failure. Use redundant network paths and switches to support failover operations.
- Physical vs. Virtual Deployments: Evaluate the pros and cons of physical servers versus virtualized environments. In some cases, virtualization can offer additional flexibility, though it must be carefully managed to avoid resource contention.
2. Configuration and Setup
- Follow IBM Guidelines: Adhere closely to IBM’s best practice documentation when setting up multi-instance queue managers. This ensures that your configuration meets all recommended performance and reliability criteria.
- Use Validated Recovery Procedures: Develop and test documented recovery procedures so that, in the event of a failure, your team knows exactly what to do.
- Automate Where Possible: Automation reduces human error. Use automation tools to handle failover testing and routine configuration checks.
3. Continuous Monitoring and Testing
- Implement Proactive Monitoring: As discussed, monitoring is crucial. Ensure that your monitoring solution can be configured to track all key metrics needed to prevent issues before they happen. This requires a purpose-built MQ monitoring solution with has granular alert parameter options that you can “stack” with multi-layered “and/or” scenarios to achieve the specific conditions you need to implement a proactive strategy. You can read more on why that’s important here.
- Regular Failover Drills: Test the failover process regularly to verify that the passive instance is ready to take over when needed. Your monitoring solution should be sophisticated enough to know that the primary has failed over and pick up the new primary until the regular primary comes back online and then switch back.
- Audit and Review: Periodically review system logs and performance metrics. Identify and address any recurring issues before they impact production.
4. Documentation and Training
- Keep Detailed Documentation: Maintain up-to-date documentation on your IBM MQ Native HA configuration, including network diagrams, configuration files, and operational procedures.
- Train Your Staff: Ensure that all relevant personnel are trained in both the technical aspects of IBM MQ and the specifics of your HA configuration. Regular training sessions and simulations can greatly improve your team’s readiness.
Below is a summary table of these best practices:
| Best Practice Area | Recommendation |
|---|---|
| Infrastructure | Use redundant shared storage and network paths; evaluate physical vs. virtual deployments |
| Configuration | Follow IBM guidelines; automate failover testing; use validated recovery procedures |
| Monitoring | Deploy proactive monitoring tools; schedule regular failover drills; analyze historical performance data, ensure monitoring solution auto switches on failover to a new pod, Qmgr, or cluster. |
| Documentation & Training | Maintain up-to-date configuration documentation; provide regular training and simulation exercises for staff |
Implementing these best practices helps ensure that your IBM MQ Native HA deployment is resilient, manageable, and scalable.
Additional Considerations and Future Outlook
Security in HA Configurations
While ensuring high availability, it is equally important to secure your messaging environment. Ensure that:
- Data Encryption: Sensitive data in transit and at rest is encrypted, especially across shared storage systems.
- Regular Audits: Conduct security audits to detect and address vulnerabilities.
- Access Controls: To achieve true high availability, any issues need to be resolved as quickly as possible. This requires a secure collaborative and proactive approach. The best administration solutions allow you to delegate administrative tasks to SMWs while ensuring that only authorized personnel have visibility and access to sensitive elements of the environment. Trusted Spaces™ allows you to do that.
Scalability and Integration with Cloud Environments
As business needs evolve, the ability to scale your messaging infrastructure becomes crucial. Consider the following:
- Cloud Integration: Many organizations are integrating IBM MQ with cloud platforms for increased flexibility. Ensure that your HA configuration can extend to cloud environments without compromising reliability.
- Hybrid Deployments: A mix of on-premises and cloud-based queue managers might be used to balance load and enhance disaster recovery capabilities.
- Future Enhancements: IBM continues to evolve its messaging solutions. Stay informed on updates to IBM MQ Native HA and related technologies by signing up for our monthly newsletter or following IBM’s official announcements and technical documentation.
Related Posts








More Infrared360® Resources












{kind=link}
{kind=link}
{kind=link}
{kind=link}